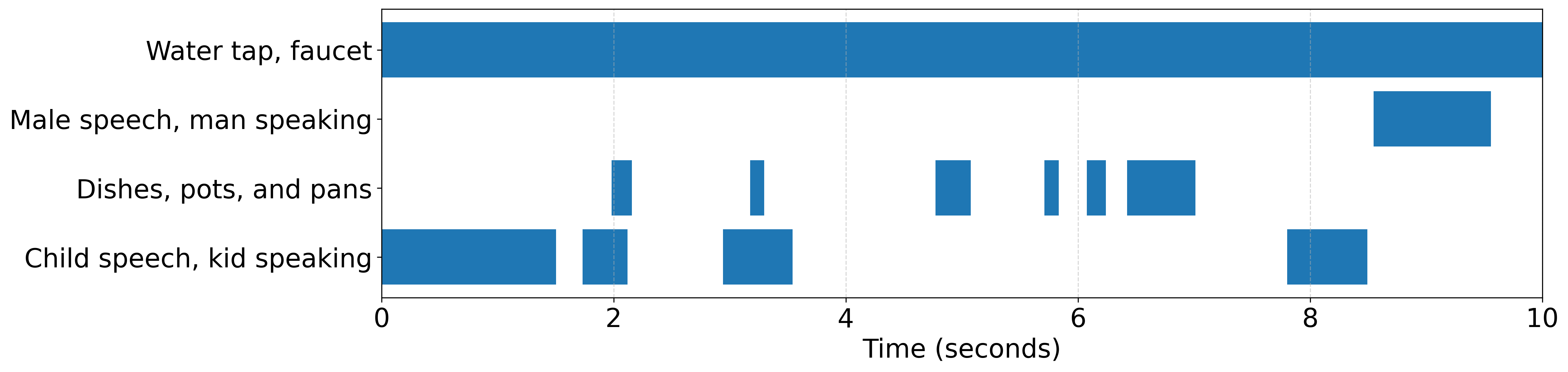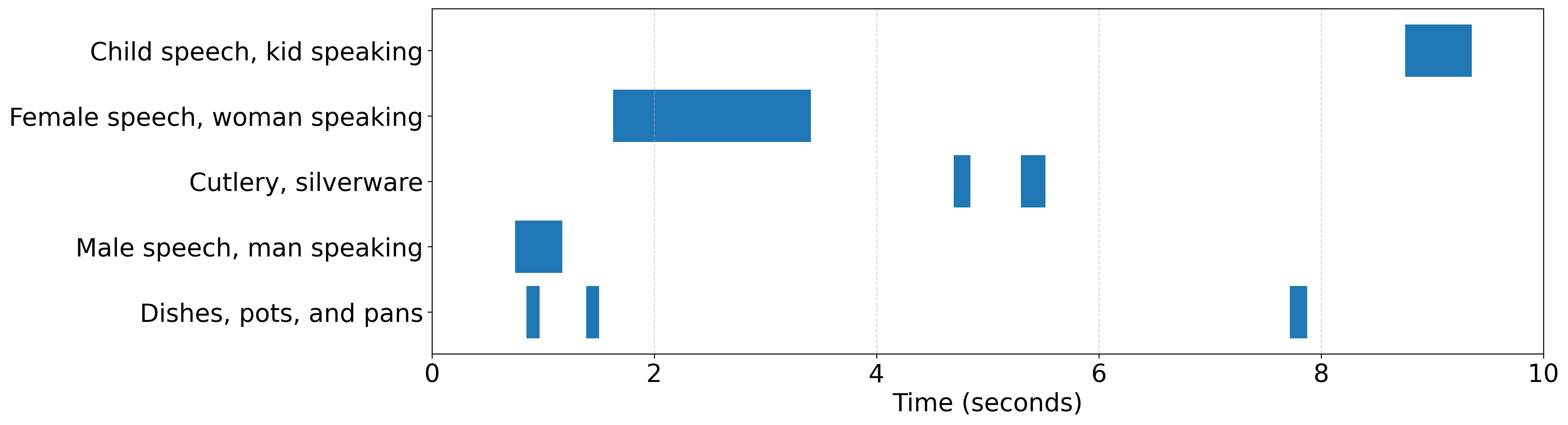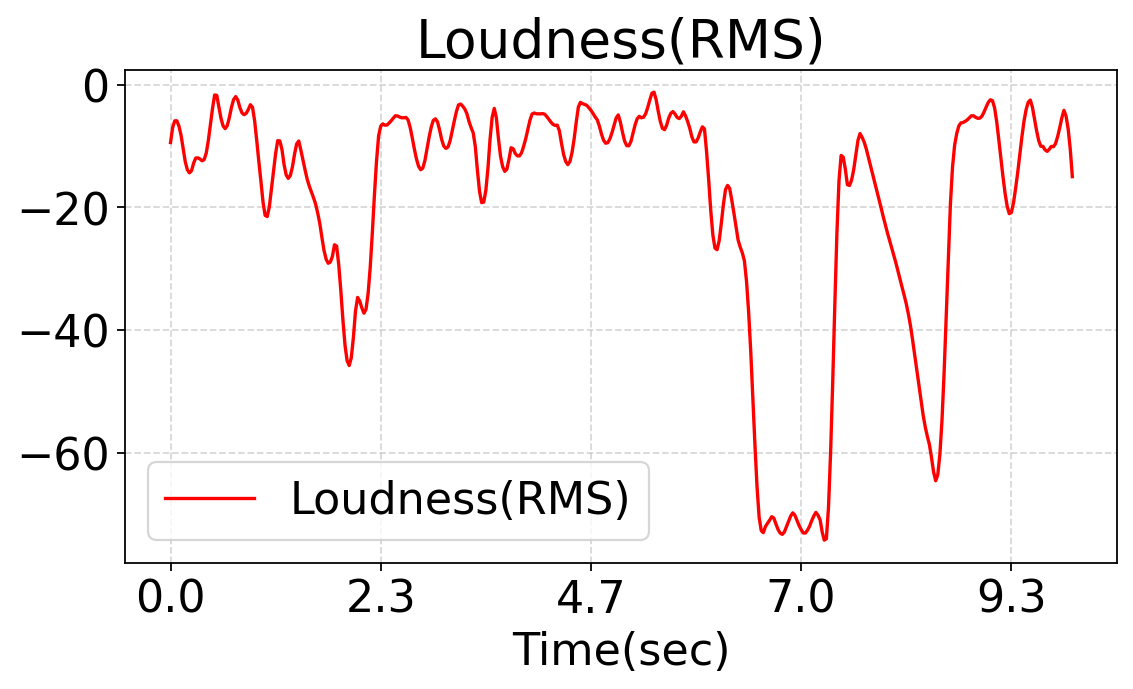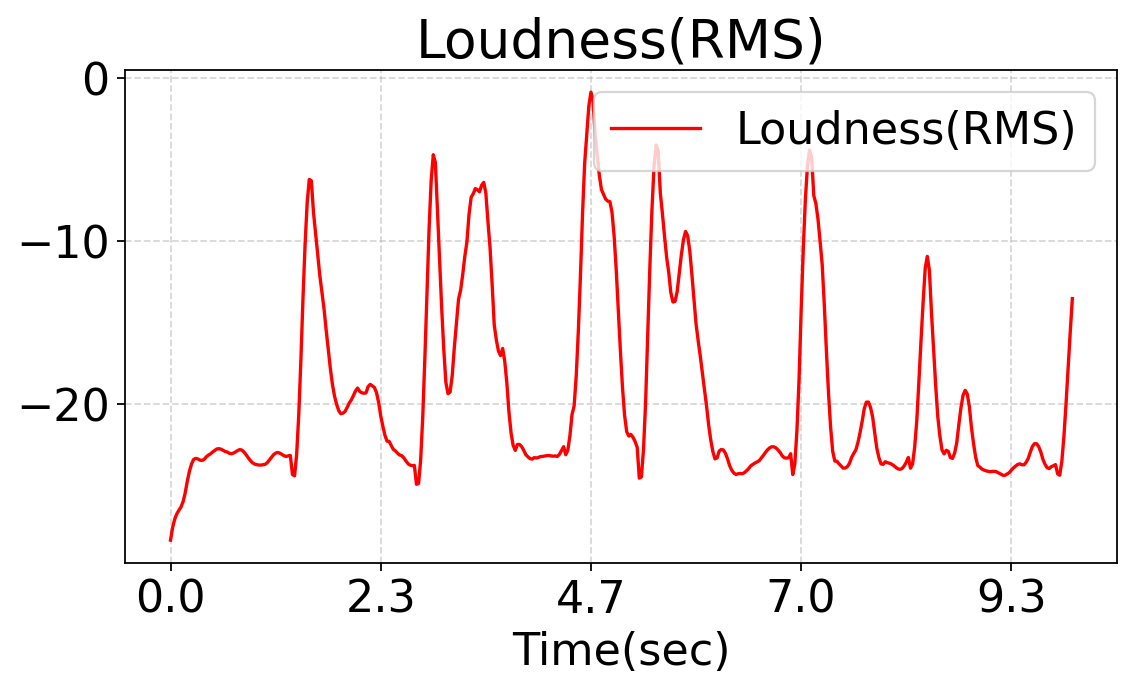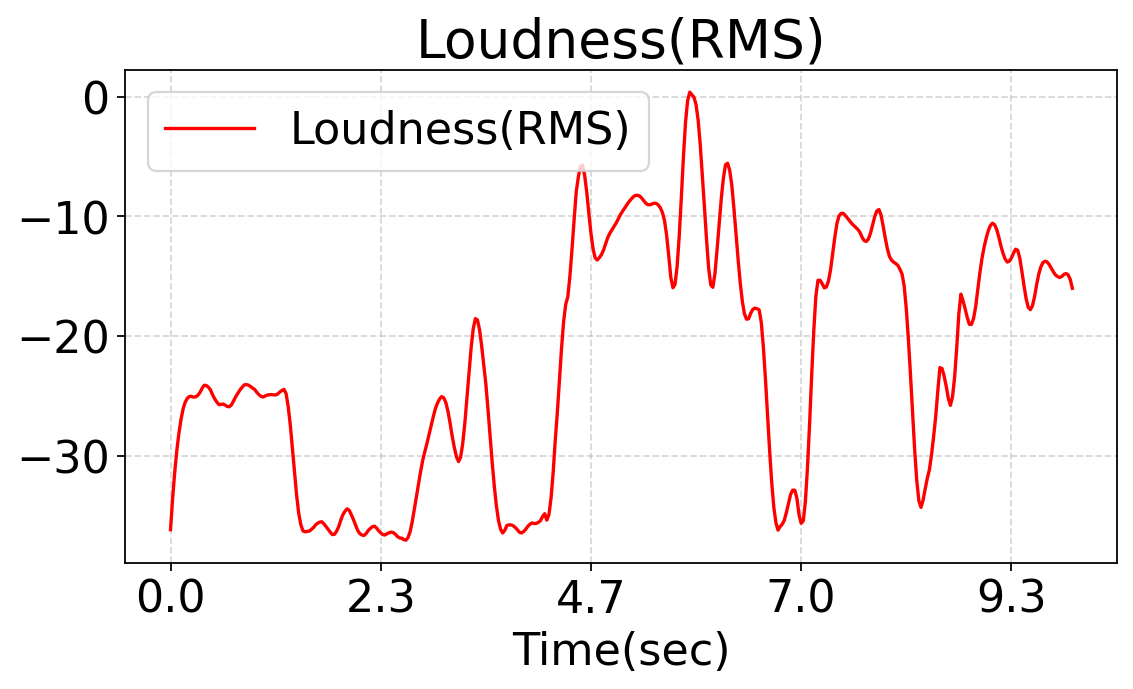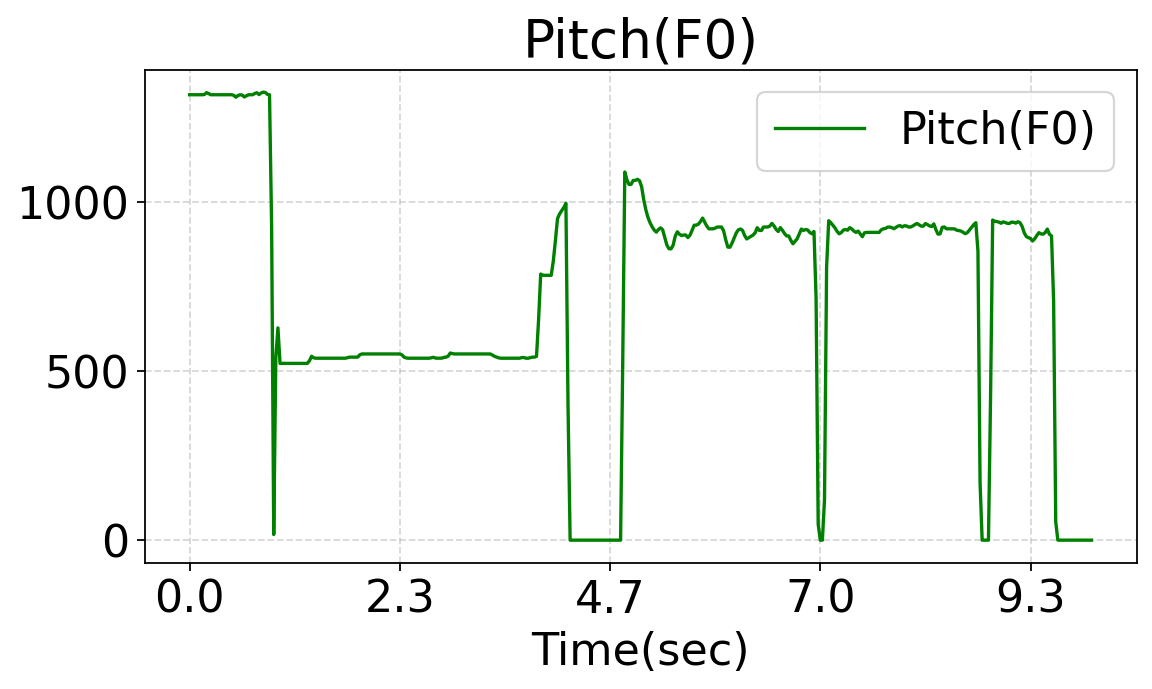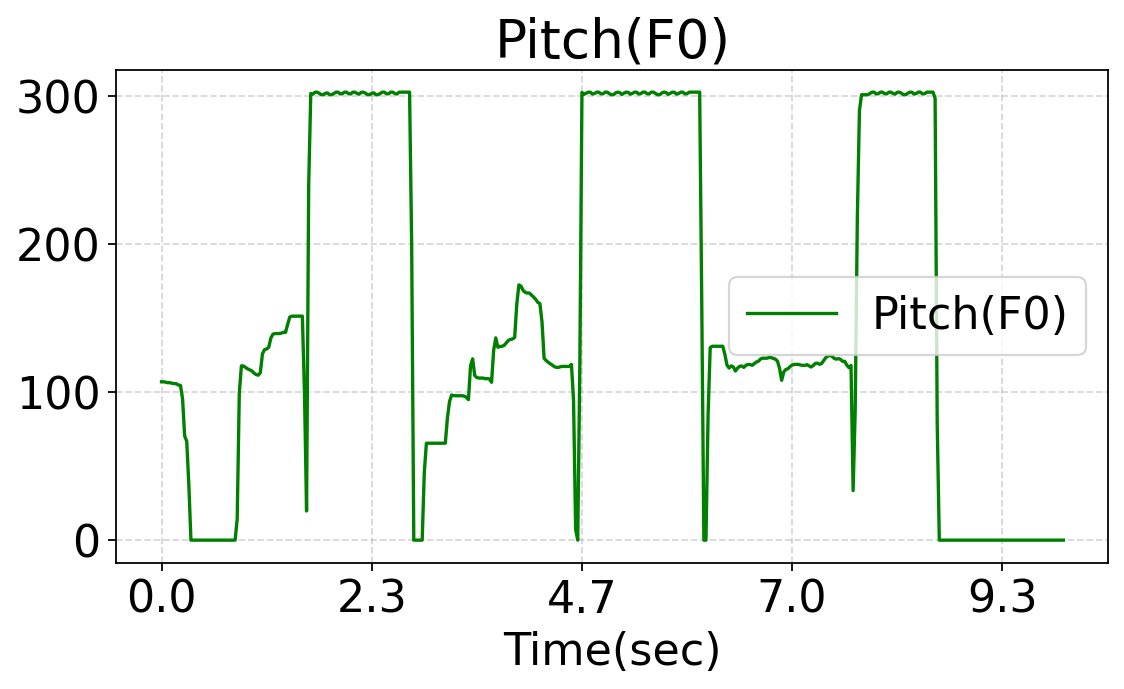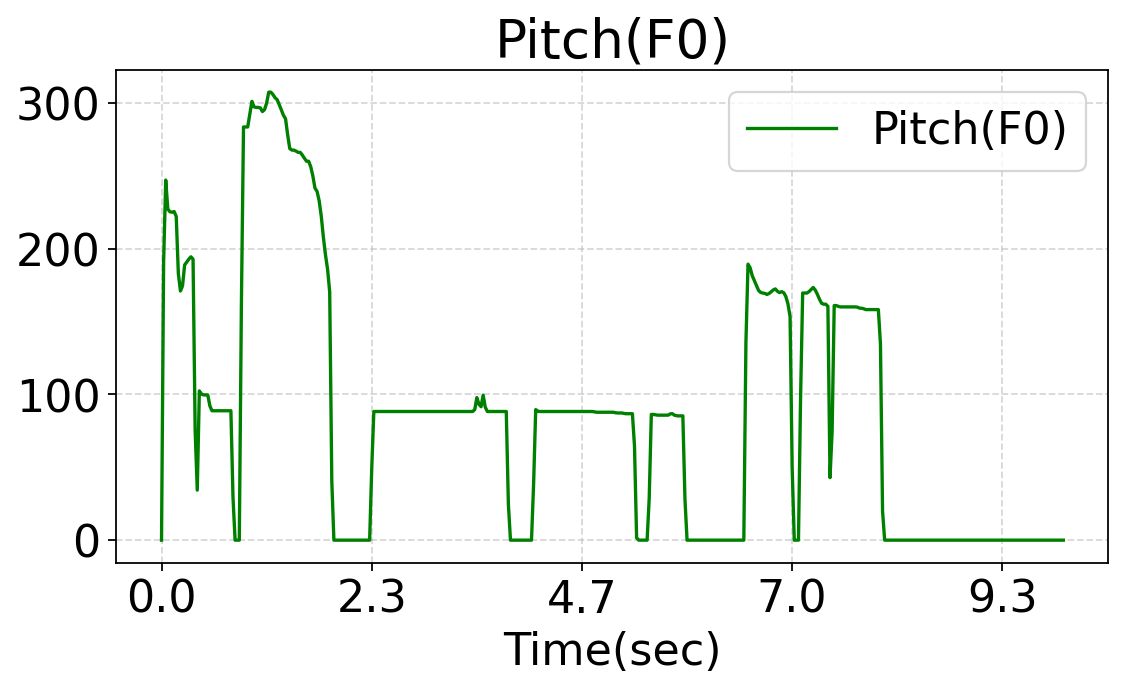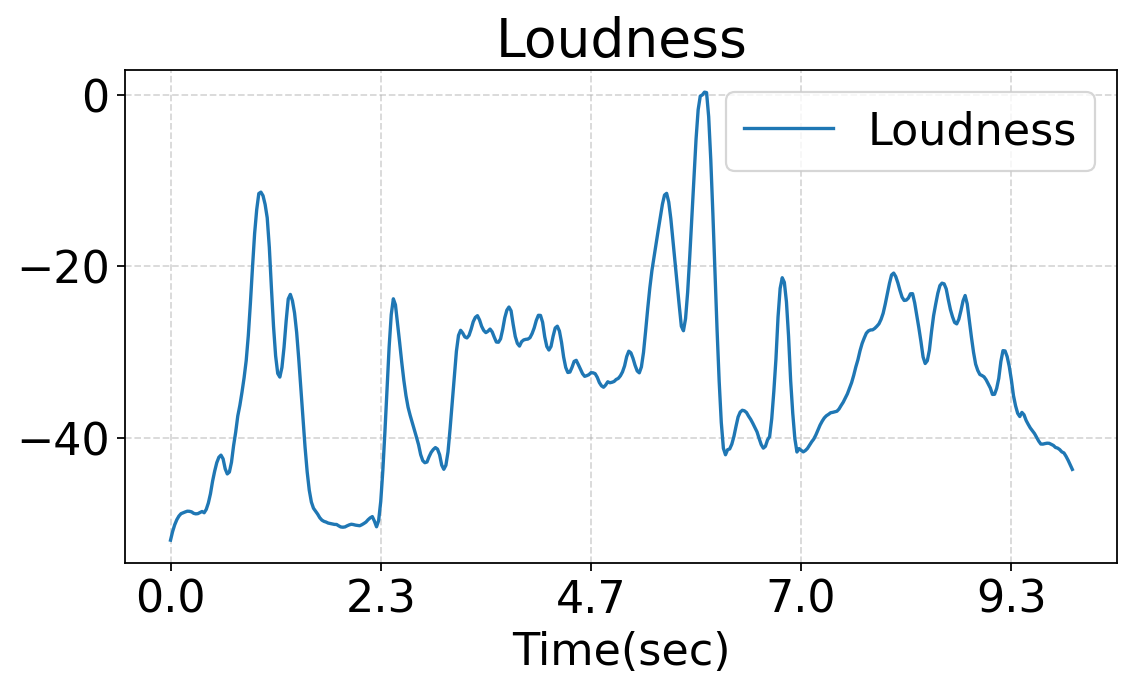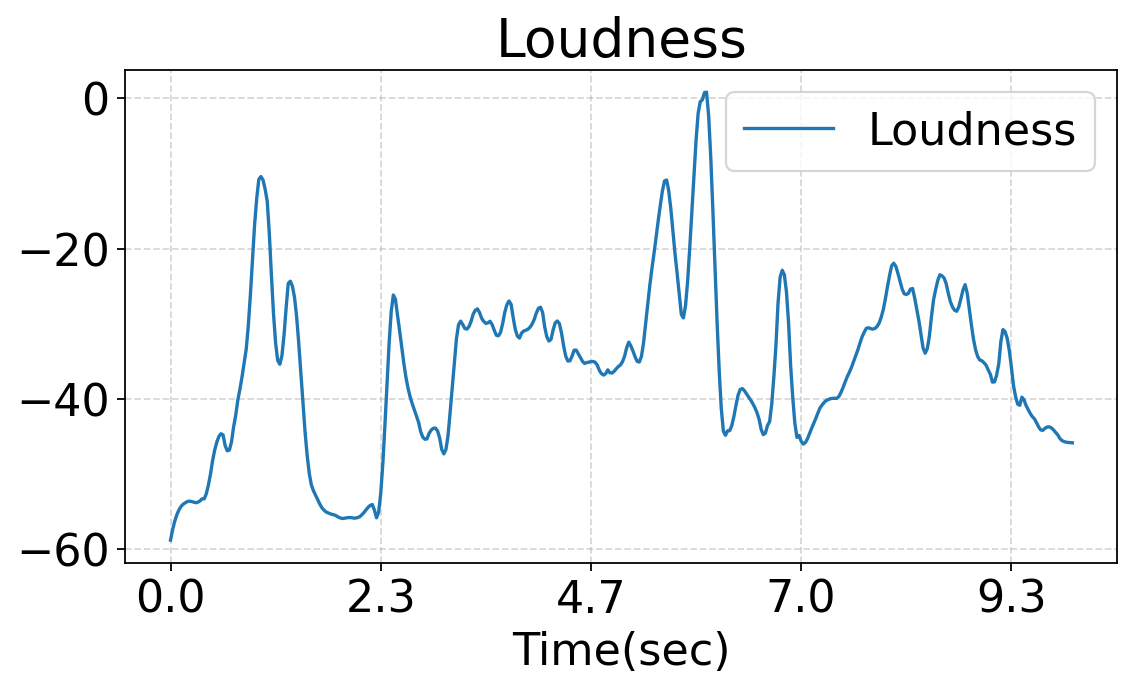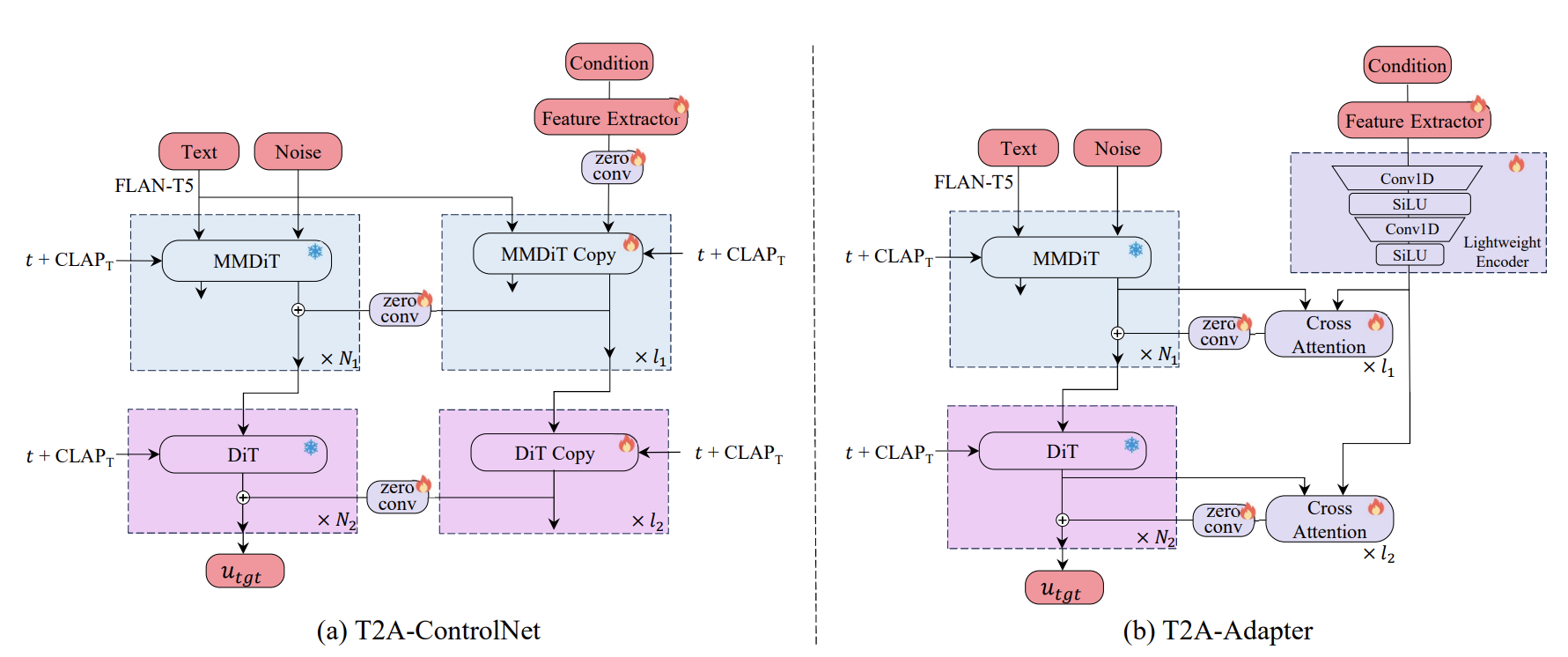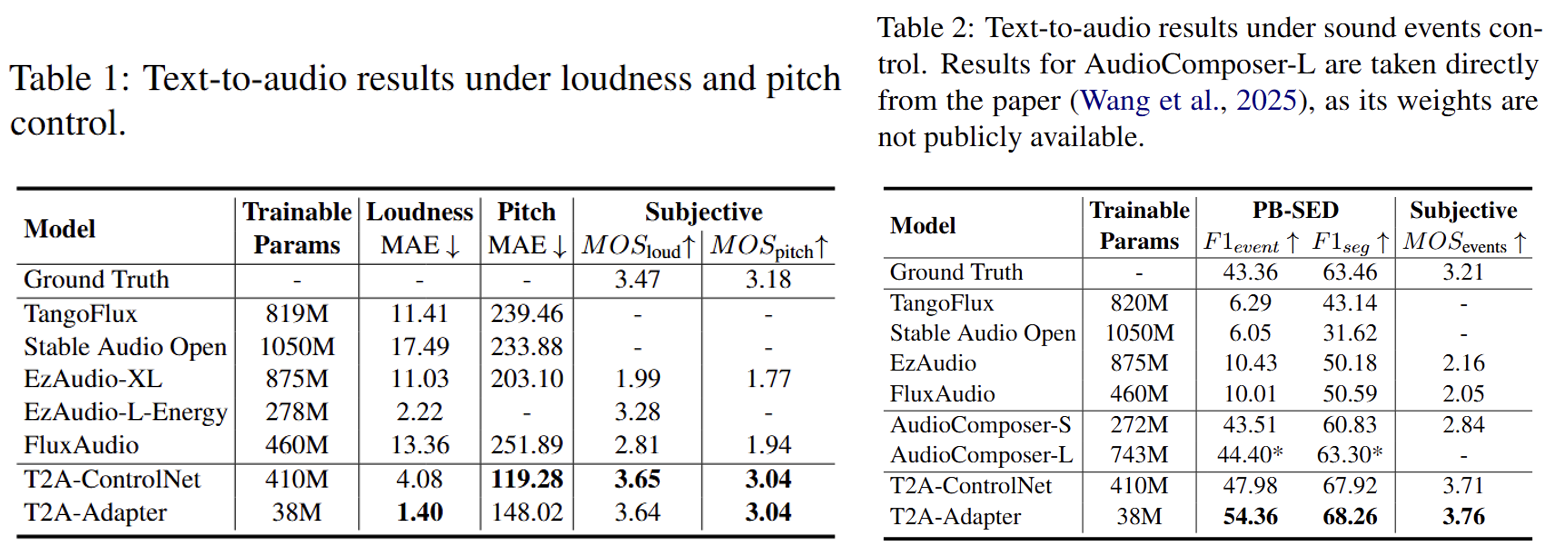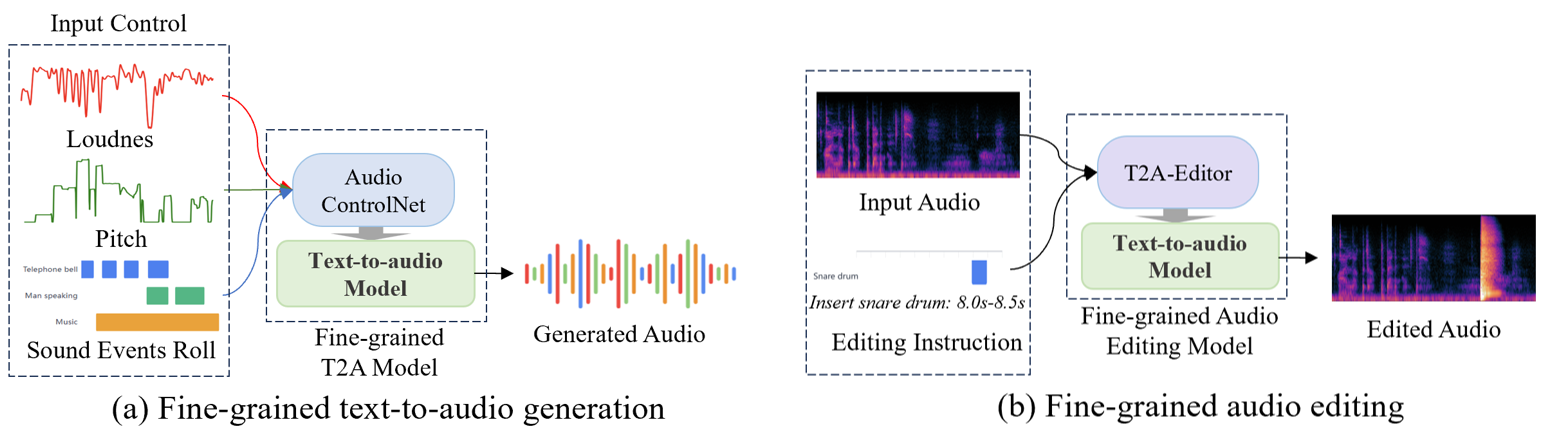
This work studies fine-grained text-to-audio (T2A) generation with explicit control over key audio attributes, including loudness, pitch, and sound events. Instead of retraining models for individual control types, a ControlNet-based framework is built on top of pre-trained T2A backbones to enable flexible and extensible controllable generation. Two designs, T2A-ControlNet and the more lightweight T2A-Adapter, are introduced. With only 38M additional parameters, T2A-Adapter achieves state-of-the-art performance on AudioSet-Strong while maintaining strong control ability. The framework is further extended to audio editing, enabling the insertion and removal of audio events at specified time locations.